재밌는걸 해보고 있다
#computer-vision, #ai-rtls, #homography•
CCTV 영상과 도면을 조합하여 CCTV 영상에서 식별한 객체를 도면 위에 표현하는 기술이다. Vision AI와 Comuter Vision을 같이 활용해야만 구현할 수 있는 기술이라는 점에서 본인에게는 난이도가 좀 있었다.

먼저 영상과 도면을 일치시켜야 한다. 3차원 공간을 투영하는 CCTV 영상과 도면을 일치시키기 위해서 Homography를 사용했다. 검색해보면 뒤지게 어려운 수식같은 게 나오는데 대충 H라고 부르는 행렬 하나만 구하면 카메라와 객체 간의 관계를 수학적으로 얻어낼 수 있는 마법같은 거라고 보면 된다. 대표적인 수포자로써 이걸 직접 계산하진 않았고, Claude Code에게 OpenCV의 findHomography 함수를 자바스크립트 기반으로 모방해달라고 요청했다.
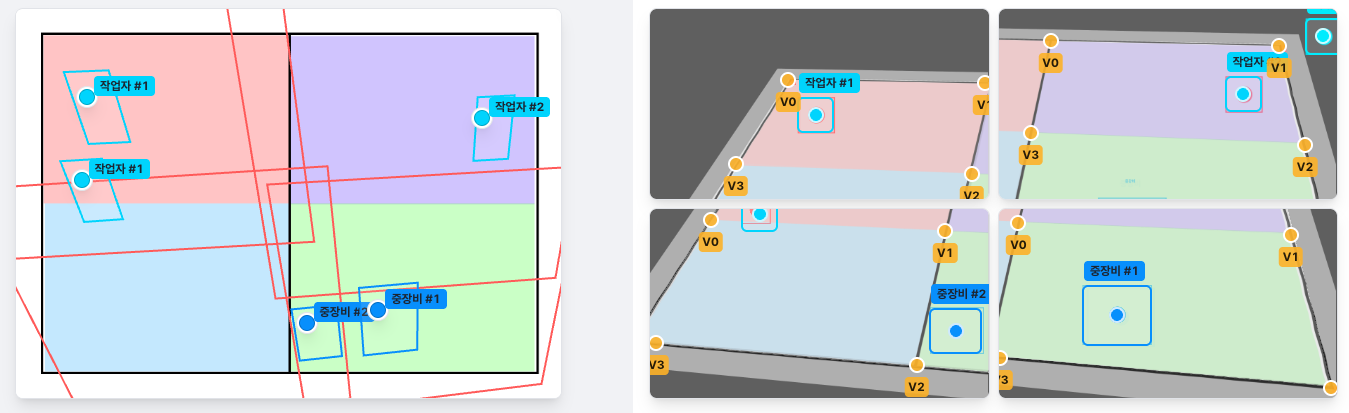
이제 카메라와 현실 세계, 도면 간의 관계를 마련했으니 이걸 활용하기만 하면 된다. Vision AI를 통해 CCTV 영상을 분석하고 영상에서 추적한 객체의 좌표를 H를 역변환하여 도면 위에 표시하는 것을 구현했다. 반대로 도면에 찍은 마커를 CCTV 영상에 투영하는 것 또한 가능하다. Vision AI 쪽은 내가 담당하진 않았지만 대충 영상을 프레임 단위로 캡처하여 Yolo 모델을 통해 객체를 인식하고 좌표를 추출하는 것 같다. 고수준의 AI 기술을 목표로 하는 것이 아니라면 객체 인식 모델은 널리고 널렸고 보편화되어 있기 때문에 취사 선택하면 된다.