Claude Code 하나로 3주간 118편의 뉴스를 자동 발행한 방법
코딩 에이전트를 뉴스룸으로. Agent Teams, commands, rules로 설계한 AI 콘텐츠 자동화 전략.
해외 AI 소식은 매일 쏟아집니다. 새로운 모델 출시, 코딩 에이전트의 업데이트, 프레임워크의 등장. 그런데 이 소식들이 한국어로 정리되어 전달되기까지는 시간이 꽤 걸립니다. 빠르면 하루, 느리면 일주일. 속보성이 생명인 AI 뉴스에서 이 간극은 꽤 치명적이라고 느꼈습니다.
동시에 Claude Code의 Agent Teams 기능이 눈에 들어왔습니다. 여러 에이전트를 정의하고, 각자에게 역할을 부여하고, 서로 소통하며 협업하게 만드는 기능입니다. 이전 글에서 AI Hub라는 협업 도구를 만들며 Agent Teams를 활용한 경험이 있었는데요. 이번에는 한 발 더 나아가 "사람의 개입 없이 콘텐츠를 자동으로 생산하는 시스템"을 만들어보고 싶었습니다.
혼자서 뉴스 미디어를 운영할 수 있을까? 설정과 프롬프트 설계에 충분히 투자하면 가능하지 않을까? 그렇게 시작된 실험이 지금의 devlery입니다.
블로그는 Next.js 기반의 정적 페이지로 구현했습니다. 이 선택에는 이유가 있습니다. AI가 블로그의 모든 컨텍스트에 접근할 수 있으려면, 콘텐츠가 파일 시스템에 존재해야 합니다. 별도의 CMS나 데이터베이스, MCP 서버 없이도 AI가 MDX 파일을 직접 읽고 쓸 수 있는 구조. 정적 블로그는 AI 자동화에 가장 자연스러운 형태입니다. 기술 선정 단계에서부터 AI와의 협업을 염두에 둔 셈이죠.
이 글에서는 블로그 개발보다는 그 위에 올린 자동화 시스템에 집중하여 이야기하려 합니다.
AI 편집부를 만들다
자동화 시스템의 구조는 실제 미디어 편집부에서 착안했습니다. 뉴스룸에는 편집장, 기자, 작가, 디자이너가 있습니다. 각자의 역할이 명확하고, 파이프라인을 따라 콘텐츠가 흘러갑니다. 이 구조를 그대로 AI 에이전트 팀으로 옮겼습니다.
| 에이전트 | 역할 | 비고 |
|---|---|---|
| 편집장 | 전체 총괄, 주제 선별, 발행 게이트 관리 | 직접 글을 쓰거나 검색하지 않음 |
| 리서처 | 웹서치로 뉴스 발굴, 심층 취재 문서 작성 | 주제를 정하지 않고 검색부터 시작 |
| 작가 | 큐레이션 글 작성, 자체 검수 | 취재 문서 기반, 뉴스 구조 준수 |
| 시각화 담당 | 썸네일 소싱, JSX 시각화 마크업 | Sonnet 모델, agent-browser 활용 |
Claude Code의 Agent Teams는 .claude/agents/ 디렉토리에 각 에이전트의 프롬프트를 마크다운 파일로 정의합니다. 각 파일에는 에이전트의 역할, 권한, 워크플로우, 제약 조건이 담겨 있습니다. 편집장이 TeamCreate로 팀을 생성하고, 각 에이전트를 스폰하여 업무를 지시하는 방식입니다.
전체 파이프라인은 이렇게 흘러갑니다.
리서처
웹서치로 뉴스 발굴, 후보 3-5개 제안
편집장
주제 선별, 심층 취재 지시
리서처
심층 취재 문서 작성
작가
큐레이션 글 작성 + 자체 검수
시각화 담당
썸네일 소싱 + 본문 시각화
편집장
최종 확인 → git commit + push
Agent Teams가 낯선 분들을 위해 간단히 설명하면, 이 기능은 Claude Code 내에서 여러 Claude 인스턴스를 동시에 실행하는 것입니다. 각 에이전트는 자신만의 독립된 컨텍스트 윈도우를 가지며, SendMessage 도구를 통해 서로 소통합니다. 편집장이 리서처에게 "이 주제를 심층 취재해줘"라고 메시지를 보내면, 리서처는 자신의 세션에서 웹서치를 수행하고 결과를 파일로 작성한 뒤 편집장에게 완료를 알리는 식입니다.
코드로 보는 자동화
이 시스템을 구성하는 실제 설정 파일들을 공개합니다. 이 글에서 공유하는 코드를 참고하면 비슷한 자동화 시스템을 직접 구축할 수 있을 것입니다.
프로젝트 세팅: settings.json
모든 것의 시작은 Agent Teams를 활성화하는 것입니다.
{
"env": {
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1"
},
"permissions": {
"allow": [
"Bash(pnpm build:*, dev:*, add:*, lint:*)",
"Bash(ls:*, git add/commit/push:*)",
"WebFetch(domain:*)",
"WebSearch",
"Bash(agent-browser *)"
]
}
}
CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS를 1로 설정하면 Agent Teams 기능이 활성화됩니다. 권한 설정에서는 에이전트들이 필요로 하는 도구들을 미리 허용해두었습니다. 웹서치와 웹페치는 리서처가, git 명령어는 편집장이, agent-browser는 시각화 담당이 사용합니다.
여기에 더해, 자동화 도중 예기치 못한 권한 이슈로 파이프라인이 멈추는 것을 방지하기 위해 Claude Code를 항상 --dangerously-skip-permissions 모드로 실행했습니다. 에이전트가 파일을 생성하거나, 이미지를 다운로드하거나, git push를 실행할 때마다 사람의 승인을 기다려야 한다면 자동화의 의미가 없기 때문입니다. 물론 이 모드는 에이전트에게 전체 권한을 부여하는 것이므로 신뢰할 수 있는 환경에서만 사용해야 합니다.
에이전트 정의: .claude/agents/
편집장 (editor-in-chief.md)
편집장의 핵심은 직접 일하지 않는 것입니다. 초기에는 편집장이 직접 웹서치를 하거나 글을 수정하는 경우가 있었는데, 그러면 편집장의 컨텍스트가 빠르게 오염되어 팀 운영에 지장이 생겼습니다.
## 핵심 원칙
- AI 뉴스 큐레이션이 중심이다
- 주제를 직접 선정하지 않는다 (리서처가 발굴하면 선별한다)
- 직접 웹서치, 글 작성, 시각화를 수행하지 않는다
## 팀 구성 (Agent Teams)
| 이름 | 타입 | 역할 |
|------|------|------|
| researcher | researcher | 최신 AI 뉴스 탐색, 트렌드 발굴 |
| writer | writer | AI 뉴스 글 작성 + 자체 검수 |
| visualizer | visualizer | 미디어 소싱 + JSX 시각화 |
발행 게이트도 편집장이 관리합니다. 블로그가 정적 페이지이므로 각 글은 MDX 파일의 frontmatter에 메타데이터를 가지는데, 여기에 images 필드가 있는지, 본문에 이미지나 영상이 1개 이상 포함되어 있는지를 확인한 후에야 발행을 승인합니다.
편집장은 두 가지 파일을 통해 콘텐츠 전체를 조망합니다.
첫째는 콘텐츠 파이프라인입니다. agent-data/content-pipeline.csv 파일로 모든 글의 상태를 추적합니다.
| id | slug | title | status | created_date | notes |
|---|---|---|---|---|---|
| 9 | vibe-coding-reality | Vibe Coding의 불편한 진실과 Spec Coding의 부상 | published | 2026-03-23 | 시각화 4개 |
| 113 | cursor-3-agent-first-workspace-ide-evolution | Cursor 3가 에디터를 버렸다, 에이전트 관제탑 선언 | published | 2026-04-08 | 시각화 4개 |
| 117 | stanford-ai-index-2026-adoption-transparency-paradox | Stanford AI Index 2026이 확인한 역설 | published | 2026-04-13 | 이미지 3개 + JSX 4개 |
| 118 | claude-mythos-preview-project-glasswing-cybersecurity | Claude Mythos Preview 공개 | published | 2026-04-14 | 이미지 2개 + JSX 4개 |
각 글은 idea → researching → researched → writing → drafted → visualizing → published 상태를 거치며, 편집장은 이 파이프라인을 보고 현재 진행 중인 작업과 완료된 작업을 파악합니다.
둘째는 콘텐츠 전략 문서입니다. agent-data/strategy/current-strategy.md 파일에는 어떤 주제 영역에 글이 몇 편 발행되었는지, 부족한 영역은 어디인지가 기록되어 있습니다. 이 문서의 핵심은 성장형 컨텍스트라는 점입니다. 편집장이 매 발행 사이클마다 이 문서를 업데이트하면서, 어떤 주제가 과도하게 다뤄졌는지, 어떤 영역이 비어 있는지를 스스로 학습합니다. 같은 주제의 중복 발행을 방지하는 장치이자, 편집팀이 매 루프마다 조금씩 성장하도록 하는 작은 시스템입니다.
리서처 (researcher.md)
리서처의 가장 중요한 원칙은 검색 먼저, 주제 나중입니다. 이 설계에는 이유가 있습니다.
처음에는 리서처에게 "AI 관련 뉴스를 찾아줘"라고만 지시했더니, 이미 알고 있는 주제를 검색하는 확증 편향이 나타났습니다. "Claude Code 업데이트"처럼 익숙한 키워드만 반복 검색하면서 정작 새로운 소식을 놓치는 문제였습니다. 그래서 주제를 미리 정하지 말고 다양한 소스를 먼저 훑은 뒤 발견한 뉴스를 제안하도록 변경했습니다.
## 핵심 원칙
- 검색 먼저, 주제 나중
- 주제를 사전에 정하지 않고 웹서치부터 시작한다
- 지금 일어나고 있는 일에 집중한다 (최근 72시간~1주일)
## 1차 스캔 소스 (반드시 먼저 탐색)
- WebSearch (다양한 키워드로 여러 차례)
- Hacker News, Reddit (r/MachineLearning, r/LocalLLaMA)
- GeekNews (hada.io)
- TechCrunch AI, The Verge AI
## 2차 심층 소스 (1차 발견 후)
- AI 기업 공식 블로그
- GitHub Trending, arXiv
- Product Hunt, X(Twitter)
리서처는 1차 스캔 후 가치 있는 뉴스 후보 3-5개를 편집장에게 제안합니다. 편집장이 승인한 주제에 대해서만 심층 취재를 진행하고, 취재 결과를 agent-data/research/{slug}-research.md 파일로 작성합니다.
취재 문서에는 핵심 요약, 배경, 중요성, 커뮤니티 반응, 경쟁 구도, 전망, 출처가 구조화되어 담기며, 특히 미디어 힌트라는 섹션이 있습니다. 리서처가 취재 과정에서 발견한 관련 이미지나 영상의 URL을 여기에 기록합니다. 이 부분은 뒤에서 다시 설명하겠습니다.
작가 (writer.md)
작가는 취재 문서를 기반으로 뉴스 큐레이션 글을 작성합니다. 중요한 것은 가이드 형식을 금지했다는 점입니다. "설치 → 사용법 → 팁" 같은 튜토리얼 구조가 아니라, 뉴스 큐레이션에 맞는 구조를 따르도록 했습니다.
## 글 구조 (가이드 형식 금지)
1. 리드(Lead) — 핵심 뉴스 한두 문단 압축
2. 배경과 맥락 — 업계 흐름, 이전 사건과의 연결
3. 핵심 내용 분석 — 구체적이고 깊이 있게
4. 실무 영향 — 개발자·실무자에게의 의미
5. 커뮤니티 반응 — HN, Reddit, X 반응
6. 전망과 시사점 — 미래 방향 예측
작가에게는 자체 검수 체크리스트도 부여했습니다. 날짜와 수치가 출처와 일치하는지, 1차 소스를 확인했는지, 리드가 핵심을 명확히 전달하는지, 최소 1500단어인지 등을 작가 스스로 점검하도록 한 것입니다. 편집장이 별도로 검수하는 것보다 작가가 자체적으로 품질을 관리하는 편이 컨텍스트 효율 면에서 훨씬 나았습니다.
또한 작가는 시각화가 필요한 지점에 마커를 남깁니다.
{/* VISUAL: 비교표 - GPT-4.5 vs Claude 4 벤치마크 성능 비교 */}
{/* VISUAL: 타임라인 - OpenAI 플러그인 생태계 발전 과정 */}
이 마커는 시각화 담당이 나중에 실제 이미지나 JSX 컴포넌트로 교체합니다.
시각화 담당 (visualizer.md)
시각화 담당은 처음부터 별도 에이전트로 존재하지 않았습니다. 이 에이전트가 분리된 배경은 시행착오 섹션에서 자세히 다루겠습니다. 핵심 역할은 두 가지입니다.
- 실제 미디어 소싱 — 공식 블로그 스크린샷, YouTube 임베드, GitHub 이미지 등
- JSX 시각화 제작 — 비교표, 타임라인, 인포그래픽 등 Tailwind CSS 기반 마크업
## 적절성 판단 기준
실제 미디어가 나은 경우:
- 제품 실제 모습 표시 필요
- 뉴스의 실체 증명 필요
- 커뮤니티 반응 규모/분위기 표시 필요
JSX가 나은 경우:
- 여러 항목 구조화 비교
- 시간순 흐름 표시
- 핵심 수치 강조
실제 발행된 글에서 시각화 담당이 제작한 JSX 마크업의 예시입니다.
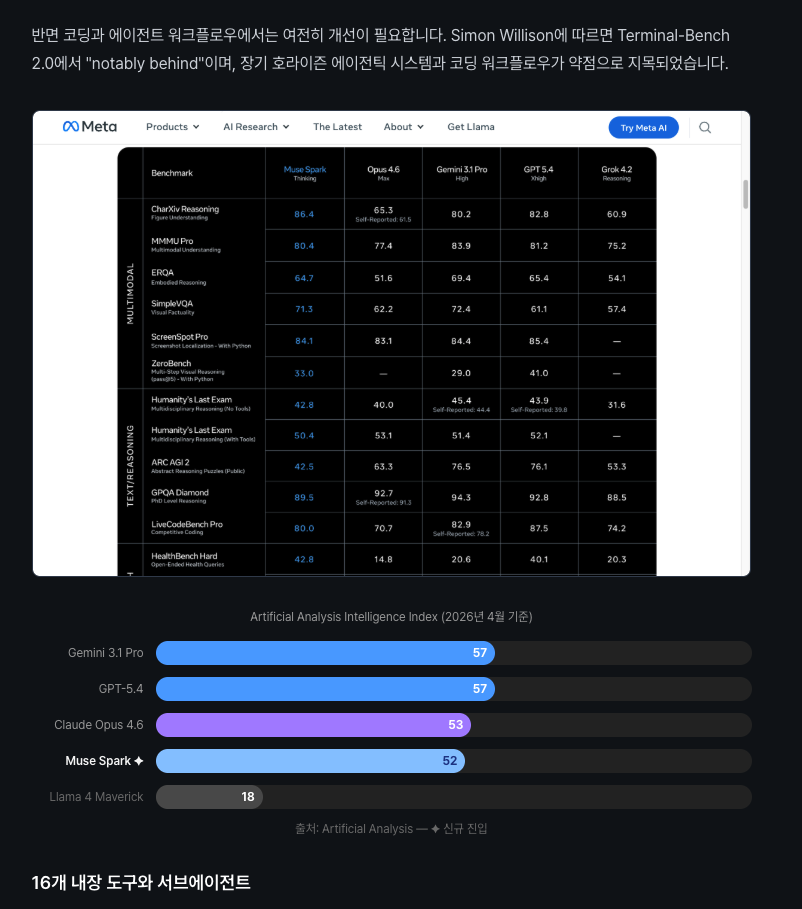

시각화 담당은 다른 에이전트들과 달리 Sonnet 모델을 사용합니다. 시각화 작업은 글 작성만큼의 추론 능력을 요구하지 않기 때문에, 비용 효율을 위해 가벼운 모델을 선택했습니다.
규칙 시스템: .claude/rules/
에이전트의 행동을 일관되게 유지하기 위해 세 가지 규칙 파일을 만들었습니다. .claude/rules/ 디렉토리에 위치한 이 파일들은 모든 에이전트가 공통으로 참조합니다.
writing-style.md
글쓰기 스타일을 통제하는 규칙입니다. 특히 AI가 생성한 글의 전형적 패턴을 깨는 것에 집중했습니다.
## 제목 규칙
- ❌ 앰대시(—) 금지 (AI 생성 글의 전형적 패턴)
- ✅ 콜론(:), 쉼표(,), 물음표(?) 사용
금지 예: iPhone 17 Pro에서 400B LLM이 돌아갔다 — 온디바이스 AI의 새 이정표
허용 예: iPhone 17 Pro에서 400B LLM이 돌아간다, 온디바이스 AI의 새 이정표
## 어조
- "~합니다/~습니다" 체
- 과도한 감탄 금지 ("정말 놀라운!", "혁명적!")
- 마케팅 표현 금지 ("최고의", "유일한", "반드시")
앰대시 금지는 사소해 보이지만, AI가 생성한 글이라는 인상을 줄이는 데 의외로 효과가 컸습니다. 규칙에 명시하지 않으면 거의 모든 제목에 앰대시가 들어갔습니다.
technical-standards.md
Frontmatter 규격, 파일 명명 규칙, 빌드 검증 절차 등 기술적 표준을 정의합니다.
## 날짜 규칙 (반드시 준수)
- date는 반드시 `date -u '+%Y-%m-%dT%H:%M:%SZ'` 명령어를 실행하여 취득
- AI가 현재 시간을 추정하거나 임의로 작성하는 것은 절대 금지
- 블로그 리스트는 date 기준 내림차순 정렬
(날짜가 틀리면 최신 글이 상단에 노출되지 않음)
날짜 규칙은 실제로 문제가 발생한 뒤에 추가한 것입니다. AI가 "지금이 대략 이 시간일 테니"라고 추정하여 날짜를 기입하면, 블로그 리스트의 정렬이 꼬이는 문제가 있었습니다.
content-guidelines.md
콘텐츠의 정체성과 품질 기준을 정의합니다.
## 콘텐츠 정체성
devlery는 AI 뉴스 큐레이션 블로그입니다.
이미 알려진 개발 가이드를 반복하지 않습니다.
## 다루지 않는 주제
- 이미 널리 알려진 개발 가이드 (React 입문, TypeScript 기초)
- 라이브러리/프레임워크의 단순 사용법
- AI와 무관한 순수 개발 도구
## 품질 기준
- 최소 1500단어
- 1차 소스 기반 팩트 체크 필수
- 한국어 자료 부족한 AI 소식 우선
- 기존 글과 주제 비중복 확인
이 가이드라인이 없었을 때는 작가가 간혹 "Claude Code 설치 가이드" 같은 일반적인 개발 가이드를 작성하는 경우가 있었습니다. 뉴스 큐레이션이라는 방향성을 명확히 규정하는 것이 중요했습니다.
자동 발행 커맨드: /auto-publish
모든 구성 요소가 갖춰진 뒤, 이를 하나의 커맨드로 묶었습니다. .claude/commands/auto-publish.md 파일입니다.
# 자동 발행
AI 편집부가 자동으로 AI 뉴스 주제 선정부터 글 작성, 시각화, 커밋+푸시까지 수행합니다.
## 실행자
editor-in-chief 에이전트
## 절차
1. TeamCreate로 팀 생성, 기존 글 확인 (중복 방지)
2. researcher 스폰 → 뉴스 후보 수신 → 주제 선별 → 심층 취재 지시
3. writer 스폰 → 취재 문서 경로 포함
4. visualizer 스폰 → 썸네일 + VISUAL 마커 + 본문 이미지
5. 발행 게이트 확인 → 파이프라인 업데이트
6. git add → commit → push origin main
7. 팀원 shutdown
Claude Code에서 /auto-publish를 입력하면 편집장이 위 절차를 순서대로 실행합니다. 주제 선정부터 git push까지 사람의 개입 없이 진행됩니다.
반복 실행: /loop
더 나아가, /loop 명령어를 조합하면 이 과정을 주기적으로 반복할 수 있습니다.
/loop 2h /auto-publish
2시간마다 /auto-publish가 실행됩니다. 뉴스룸이 24시간 돌아가는 것과 같은 구조입니다. 리서처가 최신 뉴스를 찾고, 편집장이 주제를 선별하고, 작가가 글을 쓰고, 시각화 담당이 이미지를 소싱하고, 발행까지. 이 모든 것이 반복됩니다.
숫자로 보는 성과
이 시스템을 약 3주간 운영한 결과입니다.
- 총 발행 글 수: 118편 (초기 수동 작성 12편 + 자동 발행 106편)
- 자동 발행 시작일: 2026년 3월 23일
- 일 평균 발행량: 약 4-5편
시행착오와 한계
자동화 시스템이 처음부터 완성된 형태로 나온 것은 아닙니다. 여러 번의 시행착오를 거쳤고, 아직 해결하지 못한 한계도 있습니다.
이미지 소싱의 진화
가장 많은 시행착오를 겪은 영역은 이미지 소싱입니다.
1단계: 작가/리서처에게 위임
처음에는 시각화 담당 에이전트가 없었습니다. 작가가 글을 쓰면서 필요한 이미지도 함께 소싱하거나, 리서처가 취재 과정에서 이미지까지 수집하도록 했습니다. 결과는 심각한 병목이었습니다. 이미지 소싱이라는 작업은 단순하지 않습니다. 주제와 관련된 이미지를 검색하고, 이 이미지가 적절한지 판단하고, 다운로드하여 적용하는 과정을 거칩니다. 글 작성이라는 무거운 작업과 이미지 소싱이라는 또 다른 무거운 작업이 하나의 에이전트에 몰리면서 품질과 속도 모두 떨어졌습니다.
2단계: 시각화 담당 에이전트 분리
이미지 소싱을 전담하는 시각화 담당 에이전트를 별도로 만들었습니다. 작가는 시각화가 필요한 지점에 {/* VISUAL: ... */} 마커만 남기고, 시각화 담당이 이를 실제 이미지나 JSX로 교체하는 구조입니다. 병목이 해소되었고, 각 에이전트가 자신의 역할에 집중할 수 있게 되었습니다.
3단계: Web Fetch의 한계와 Playwright 도입
시각화 담당이 분리된 후에도 문제가 있었습니다. 단순 WebFetch로는 접근할 수 없는 사이트가 많았습니다. JavaScript로 렌더링되는 페이지, 로그인이 필요한 사이트, 동적 콘텐츠가 포함된 페이지 등. 이를 해결하기 위해 Playwright를 도입했습니다.
4단계: agent-browser로 최적화
Playwright 자체도 문제가 있었습니다. 스크린샷을 캡처하고 LLM이 그 스크린샷을 분석하여 다음 행동을 결정하는 고전적인 방식을 사용했기 때문에, 이미지 하나하나에 드는 공수와 토큰이 상당했습니다. 이를 해소하기 위해 Vercel이 만든 agent-browser를 적용했습니다. 접근성 트리 기반으로 페이지를 분석하기 때문에 스크린샷 없이도 페이지 구조를 파악할 수 있어, 토큰 소비가 크게 줄었습니다.
5단계: 리서처의 미디어 힌트
마지막 최적화는 리서처 쪽에서 이루어졌습니다. 초기에는 작가가 글을 쓰면서 VISUAL 마커에 설명만 남기고, 시각화 담당이 처음부터 관련 이미지를 찾아야 했습니다. 그런데 리서처가 취재하는 과정에서 자연스럽게 관련 미디어를 접하고 있었습니다. 공식 블로그의 히어로 이미지, YouTube 데모 영상, GitHub README의 스크린샷 등. 이 URL들을 리서치 문서의 "미디어 힌트" 섹션에 기록하도록 했더니, 시각화 담당의 이미지 소싱이 훨씬 수월해졌습니다. 속도 향상보다도 이미지 소싱의 정확도, 즉 보다 적절한 이미지를 선정하는 데에 크게 기여했습니다.
컨텍스트 윈도우의 벽
/loop 2h /auto-publish는 하나의 세션 내에서 반복 실행됩니다. 이것은 중요한 제약을 의미합니다.
대략 8편 정도의 글을 자동 발행하면 편집장의 컨텍스트 윈도우가 거의 포화됩니다. 현재 1M context를 사용하고 있어 가용 공간은 넉넉하지만, 컨텍스트가 과하게 쌓이면 예상치 못한 동작이 발생합니다. 가장 흔한 문제는 지시 이탈입니다. 프롬프트에서 "편집장은 직접 업무를 수행하지 않는다"고 명시했음에도 불구하고, 컨텍스트가 길어지면 편집장이 직접 글을 쓰거나 Agent Teams 대신 서브에이전트를 사용하는 등의 문제가 나타났습니다.
때문에 하루에 한 번씩 세션을 점검하고 사람이 직접 재실행해줘야 했습니다. 완전한 무인 운영과는 아직 거리가 있는 셈이죠.
이 문제를 해결하기 위해 Claude Code의 스케줄링 기능을 검토했습니다. Claude Code는 CronCreate를 통해 크론잡을 생성할 수 있고, Cloud 스케줄(Anthropic 클라우드에서 실행)과 Desktop 스케줄(로컬 머신에서 실행) 두 가지 방식을 제공합니다. 로컬에서 Claude Code를 실행하는 우리의 경우 후자에 해당합니다. /loop과 달리 세션에 종속되지 않고, 매 실행마다 새로운 세션이 시작됩니다.
사실 컨텍스트 초기화는 오히려 장점이 될 수 있습니다. 매 글마다 신선한 시각이 중요한 뉴스 큐레이션에서는, 이전 글 작성의 맥락이 쌓여 편향이 생기는 것보다 깨끗한 컨텍스트에서 시작하는 것이 목적에 더 부합합니다. 영구적으로 유지해야 할 컨텍스트(발행 이력, 콘텐츠 전략 등)는 이미 파일로 관리하고 있으므로, 세션이 초기화되더라도 편집장이 파일을 읽어 필요한 맥락을 복구할 수 있습니다. 오히려 컨텍스트를 절약하면서도 안정적으로 운영할 수 있는 방안입니다.
그러나 현실적인 문제가 있습니다. Agent Teams는 대화형 세션에서만 작동합니다. 크론잡은 비대화형(non-interactive) 모드로 Claude Code를 실행하는데, 이 모드에서는 TeamCreate나 SendMessage 같은 Agent Teams 도구를 사용할 수 없습니다. Agent Teams는 본질적으로 사용자가 팀 리드와 상호작용하며 팀원을 관리하는 구조이기 때문입니다. 결국 크론잡으로 자동화하려면 Agent Teams 없이 동작하는 구조, 즉 서브에이전트 기반의 설계로 전환해야 합니다.
품질 편차와 프롬프트의 반복 수정
자동 생성된 글의 품질은 일정하지 않습니다. 어떤 글은 분석이 깊고 구조가 탄탄한 반면, 어떤 글은 표면적인 요약에 그치기도 합니다. 이 편차를 줄이기 위해 프롬프트를 수차례 수정했습니다.
대표적인 예가 앞서 언급한 앰대시 금지입니다. AI가 생성한 글의 전형적인 패턴들, 과도한 감탄사, 마케팅 투의 표현, 앰대시로 연결된 부제 등을 하나씩 발견할 때마다 rules 파일에 금지 조항을 추가했습니다. 규칙이 구체적일수록 품질이 안정되었습니다.
비용도 무시할 수 없습니다. Agent Teams는 각 에이전트가 독립된 컨텍스트 윈도우를 가지므로, 4명의 에이전트가 동시에 작동하면 대략 4배 가까운 토큰을 소비합니다. 한 편의 글을 발행하는 데 드는 비용이 적지 않으며, 시각화 담당이 이미지를 소싱하는 과정에서 추가 토큰이 크게 발생합니다.
다음 방향
이 실험을 통해 Claude Code의 Agent Teams로 콘텐츠 자동화가 가능하다는 것을 증명했습니다. 하지만 동시에 개선의 여지도 명확히 보였습니다.
Agent Teams의 강점은 에이전트 간 소통입니다. 편집장이 리서처에게 피드백을 주고, 작가가 시각화 담당에게 맥락을 전달하는 과정에서 글의 품질이 높아집니다. 그러나 트레이드오프로 토큰 소비가 높습니다. 각 에이전트가 독립된 컨텍스트 윈도우를 유지하고, 에이전트 간 메시지 교환에도 토큰이 소비되기 때문입니다.
여기서 주목할 만한 대안이 서브에이전트(Agent tool) 기반 설계입니다. 서브에이전트는 메인 에이전트가 하위 작업을 위임하는 방식으로, Agent Teams와 달리 에이전트 간 직접 소통은 없지만 토큰 효율이 높습니다. 서브에이전트는 자신의 작업에 필요한 최소한의 컨텍스트만 가지고 시작하며, 내부에서 수십 번의 도구 호출이 일어나더라도 중간 과정의 토큰이 메인 에이전트의 컨텍스트를 소비하지 않습니다. 결과만 요약되어 반환되기 때문입니다.
Agent Teams에서는 편집장의 컨텍스트에 리서처, 작가, 시각화 담당과의 모든 메시지가 누적되지만, 서브에이전트 방식에서는 "리서치 완료, 결과는 이 파일에 있습니다"라는 요약만 돌아옵니다. 이 차이가 장기 운영에서의 안정성과 비용에 직접적인 영향을 미칩니다.
커맨드와 룰을 잘 설계하고, 서브에이전트에게 명확한 지시를 내리는 하네스 구조를 만들면, Agent Teams까지 갈 필요 없이도 고품질의 자동 발행 시스템을 구축할 수 있을 것으로 기대합니다. Agent Teams로 증명한 가능성을, 더 효율적인 구조로 발전시키는 것이 다음 과제입니다.
설정과 프롬프트 설계에 충분히 투자하면, 혼자서도 뉴스 미디어를 운영할 수 있다는 것을 이 실험이 보여주었습니다. 완벽하지는 않지만, 가능성은 충분히 증명되었다고 생각합니다.
이 글에서 공유한 설정들은 devlery 블로그의 실제 설정을 기반으로 합니다. 자신만의 자동화 시스템을 만들어보고 싶으신 분들에게 참고가 되었으면 합니다.
부족한 글 읽어주셔서 감사합니다.
Devlery
Devlery는 이 글에서 소개한 자동화 시스템으로 운영되는 AI 뉴스 큐레이션 블로그입니다. AI 모델 출시, 코딩 에이전트 업데이트, AI 프레임워크 동향 등 해외 AI 소식을 빠르게 한국어로 큐레이팅합니다. 매일 새로운 글이 자동으로 발행되고 있으니, AI 업계 동향이 궁금하신 분들은 방문해보세요.